ISA
ISA는 Instruction Set Achitecture의 줄임이란 걸 밝히고 시작한다.

위 그림은 CPU의 종류중 하나인 MIPS의 ISA 예시이다. 솔직히 봐도 무슨 내용인지 정확히는 모르겠지만, Comments 부분을 주목해 읽어보니 Arithmetic(산술연산) 포맷, Transfer, Branch, Jump 등등이 눈에 띈다.
만약 C언어에서 덧셈을 하는 코드를 짰다면, 우선 그것이 어셈블리어의 add 명령어로 변환이 된다. 이때 add명령어는 산술연산(Arithmetic)에 해당하므로, 위 그림에서 R-format에 해당하는 Intruction이 관계될 것으로 추측할 수 있다.
시간측정
일반적으로 CPU 퍼포먼스를 측정할 때, 우리는 실행 시간을 기준으로 그것을 측정하게 된다.

또한 이렇게 얻어진 퍼포먼스 값을 다른 값과 비교할 때, 다음과 같이 서로 비례시켜 얼마나 빠른지를 이야기할 수 있다.

따라서 다음 예제를 볼때, X의 실행시간이 5시간, Y는 10시간이라면 퍼포먼스 값을 비교하여 X가 2배 더 빠르다고 이야기할 수 있게 되는것이다

Clock Cycle Time

컴퓨터에서 정말 낮은 로우레벨 단계에서는, 0과 1의 연산이 수없이 많고 빠르게 이루어진다. 그 과정을 확대해보면 위 그림과 같은데, 0->1->0을 오가는 과정을 하나의 Cycle이라고 하고, 한 Cycle을 도는데 필요한 시간을 Clock Cycle Time이라 한다. 또한 Clock Rate는 Clock Cycle Time을 역수로 취한 값이며, 1초에 몇 번이나 싸이클을 도는지 나타낸다. 단위로는 Hz, MHz, GHz가 쓰인다. Hz보다 GHz가 1초에 더 많은 싸이클을 돌기 때문에 Clock Rate가 높을수록 컴퓨터의 성능이 좋다는 것을 의미한다.
//TMI로 요즘은 2GHz 이상의 CPU 성능을 지향하기보단, 코어의 수를 늘리는 쪽으로 컴퓨터 성능을 향상시키고 있다는데 교수님이 이 부분은 나중에 설명해주신다고 했다. 확실히 다나와같은 곳 보면 2GHz 이상의 수치는 못본듯

아무튼 결론적으로, 실행시간은 위와 같은 식으로 구해지게 된다. 당연히 돌아야 하는 싸이클이 적을수록(분자가 적을수록), 1초에 돌릴 수 있는 싸이클이 많을수록(분모가 클수록) 실행시간의 값은 적어질 것이다.
CPI
위 내용을 보고나니 우리가 만든 코드가 얼마만큼의 싸이클을 만들어내는지가 궁금해진다. 참고로 CPI는 Cycle Per Instruction의 줄임이다. (아까 위에서 봤던 ISA의 Instruction과 같다) 이 Instruction은 어떤 연산(Add, branch 등등)을 수행할때 얼마만큼의 싸이클을 도는지 정의하고 있다.
+ 그런데 CPU 종류에 따라서 같은 연산을 수행하더라도 요구하는 싸이클의 수가 다르기도 하다. 예를들어, 인텔의 경우 Add연산에 2싸이클을 소모하지만 ARM은 1싸이클만을 소모하는 상황 같은 것이다. 이런 차이로 인해 CPU마다 퍼포먼스의 측정값이 달라질 수 있다. MIPS로 컴파일러 간 성능비교를 할 때 동종의 CPU 환경에서 진행해야 하는 이유도 이런 맥락에서 이해할 수 있다.
예제를 하나 보자.
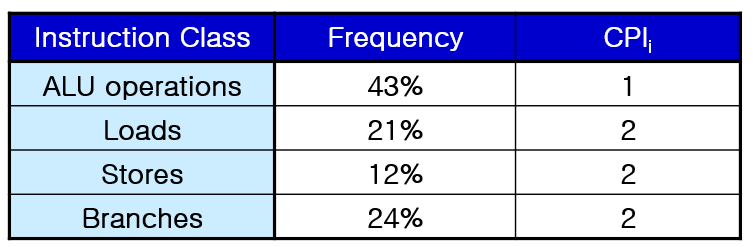
내가 만든 코드에서 ALU 기능의 빈도가 43퍼, Load 기능이 21퍼, Stores 기능이 12퍼, Branches 기능이 24퍼의 빈도를 갖는다고 하자. 그렇다면 평균 CPI는 다음처럼 빈도에 CPI를 곱해 값을 구하면 된다.

즉, 한 기능(Instruction)을 수행하는데 평균적으로 1.57 싸이클을 필요로 한다는 것을 알 수 있다.
또 다른 예제를 보자.

위 CPU에서는 ALU(산술) 기능에 1CPI, Load/Store 기능에 2CPI, Branch 기능에 3CPI를 요구한다.

이때, 컴파일러1은 CPU에 잘 맞게 설계되어서 ALU기능이 5번만 호출되었다. 그런데 컴파일러2는 그렇지 않아서 산술 기능에 많은 Instruction counts를 부여하게 되었다.

이 경우, 컴파일러1의 클록 싸이클은 10M, 컴파일러2의 클록 싸이클은 15M이 된다.

...따라서 컴파일러1의 실행시간이 0.01 더 빠르다는 것을 알 수 있다.
만약 컴파일러2의 실행시간을 개선하고 싶다면, ALU 기능에 해당하는 부분을 고치는 것이 더 효율적일 것이다. 왜냐면 전체 기능 중 ALU에 해당하는 Instruction이 제일 많으므로, 이 부분을 개선할 수 있다면 전체 프로그램의 속도 향상에 많이 기여할 것이기 때문이다. 만약 Load/Store의 성능을 2배나 개선한다고 하더라도, 전체 프로그램에서 차지하는 비중은 낮기 때문에 성능 향상에 큰 변화가 없을 것이다. 이와 관련한 개념이 바로 '암달의 법칙' 이라고 한다.
'개발 > 컴퓨터과학' 카테고리의 다른 글
| 최소 스패닝 트리 (MST) + 백준 1197번 (1) | 2024.03.11 |
|---|---|
| FLT_MIN의 언더플로우, 왜 이미 최솟값인데도 계속 나누기가 가능할까? (0) | 2021.03.09 |